It’s Alex and Fiona’s herfstvakantie now, and I am off work as well. I’ve spent some of the time consolidating photos from the various places they’ve ended up into a single archive location. This is not a trivial task.
We’ve been taking digital photos since 2000, and we have owned a fair few digital cameras and phones with cameras in that time. After consolidation I’m looking at a folder structure containing 46,947 items, taking up 114GB of space. This is mostly photos, with a few videos as well.
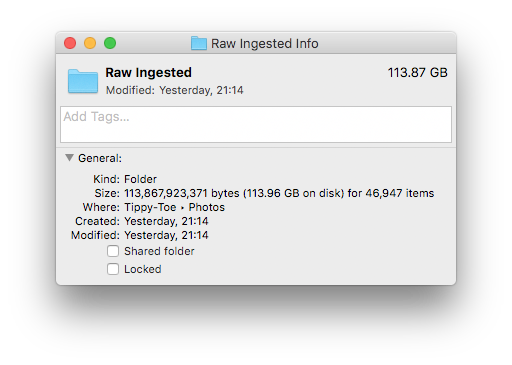
Here are the main sources I’ve been consolidating the photos from:
- Folders on my hard disk. In the era before phone cameras, I copied photos off of memory cards and into a single date-based folder structure. But inevitably there are stragglers all over the place, in directories like
/pictures,/photos, and/pictures/photos. - Dropbox, from the time when I was using its camera upload functionality. Over time, this evolved from “attach phone or memory card and let Dropbox do its thing” to “upload directly from my phone using the Dropbox app”.
- Google Photos, from the time I was using a variety of Android phones (mainly a Nexus 4), and Google would upload pictures directly to its cloud storage.
- Microsoft OneDrive, from recent usage. It uploads photos from my Lumia 930 directly to cloud storage. I started using this because the Dropbox app on Windows Phone (which should do exactly the same thing) was crashy and unreliable.
- iPhoto. For a while between about 2010 and 2014, I imported photos into iPhoto for easier viewing and manipulation of things like orientation and date.
- Apple Photos. In 2015, Apple’s new Photos app took over from iPhoto, and “imported” everything that was already in iPhoto. It also became the repository for my “Photo Stream”, which I still haven’t figured out completely.
This setup is problematic in terms of consistency: where do I look for a photo? First of all, it’s nice to have all of your photos in a single place. But also, without consistency, it’s hard to do good backups. Dropbox, Google Photos, and OneDrive may be cloud storage solutions where you don’t have to take care of backups yourself…but that doesn’t mean I trust them. Cloud services get shut down or die all the time. I prefer the belt and braces approach, where I maintain local backups (copies on multiple hard drives) combined with an off-site cloud backup (currently Crashplan).
Also, just browsing through folders of photos using the Finder on macOS or Explorer on Windows is…ok, but primitive. It’s certainly not fun. Dropbox’s web interface for browsing photos online is…functional. OneDrive is prettier, but unusably slow. iPhoto was pretty, but mainly local. Apple Photos is less pretty, but more functional; mostly local, but with cloud-like sharing capabilities. Google Photos is simple, good for sharing, but less functional.
Then there’s the whole issue of duplication. Something like Apple Photos is designed to import photos into its own library format. With Google Photos you upload your photos to Google, and it handles them remotely. In both cases, you end up with your source photos, and a copy of them in a library. You can do things to the copy, like add descriptions, or group them into albums; the source files are unaffected. On the one hand: the library allows you to do useful things! On the other hand, your useful things are only available in the library. If you decide you want to use a different software tool a few years down the line, what happens to all the work you spent editing the copies? Do you abandon that, or is there an export tool that allows you to take your edits with you? With the new library respect the metadata that came from the old one? And if you export your library, what do you do with the originals? Are they still relevant, or has the copy now become the new primary source?
Segals’s law says, “A person with a watch knows what time it is. A person with two watches is never sure.” Duplication is why it has taken me several days to consolidate my photos.
- There were times in the past when I was copying photos off of my camera’s memory card, as well as letting Dropbox automatically upload the files.
- When I was using the Nexus 4, I had Dropbox camera upload running as well as Google’s own Photos import.
- For a while I was using Dropbox camera upload on my Lumia 930, and copying the files onto my hard disk manually, because the Dropbox app was so unreliable
- On my iOS devices (iPhone 4 in the past, iPad mini now), photos generally go into Apple’s “Photo Stream”. From there, they usually end up on my laptop, in iPhoto or Apple Photos. (Usually, but not always.) And I usually have Dropbox doing its thing on iOS devices as well.
- When Apple Photos was released, I tried it, and imported a copy of my iPhoto library.
Ugh. All these import services use different naming standards, sometimes remembering the camera’s original file name, sometimes attaching their own. If they used a date/time file name (e.g. 2016-10-20 11.21.59.jpg), usually these dates match, but not always. (OneDrive and Dropbox caused the most disagreements.)
But not only that: with the exception of pulling images off of a memory card or phone manually, all of these magical import/upload processes are less than 100% reliable. (They’re close, but definitely not 100%.) Sometimes they just fail to grab one or more pictures out of a batch. Sometimes the Apple Photo stream doesn’t copy pictures to the Photos app. The iPhoto to Apple Photos library import failed to copy a bunch of videos. This all adds up to many hours of work, manually checking folders against each other, deleting duplicates, and copying missing items. (Fortunately this was only for pictures from mid-2011 and onwards. I wasn’t using overlapping automated tools before then.)
As an aside, my camera usage has shifted substantially over the last five years. Although we still have our old Konica Minolta DiMAGE A200, I hardly use it at all now. On our trip to California in the summer, I didn’t even bring it with us. But reviewing thousands of photos from mixed sources in a short span of time has made it abundantly clear that the ten-year-old consumer-level A200 (which isn’t even a DSLR) still takes much better photos than the best of the smartphones we use right now.

There are features that the A200 lacks. Portability is the big one. I always have my phone with me; bringing the big camera makes any trip feel like an undertaking. It still uses old and slow CF memory cards; the auto-focus is relatively slow; the camera doesn’t have GPS for adding location to photos; it doesn’t even have an orientation sensor, which means lots of sideways photos to review. But the image quality makes me think that I shouldn’t be pining for a new phone, but looking for a new dedicated camera instead. The current crop of “superzoom” cameras looks amazing.
Having just trawled through thousands of photos, I’m keen not to repeat that experience. I want a process that will make it easier for me to gather, review, and share my photos in the future. The process has to separate four key stages: ingest, consolidate, tag, and share.
The first part, ingest is all about getting photos off of the camera or device. On a smartphone/tablet that could be Dropbox, OneDrive, or Apple’s Photo stream — I don’t really care, so long as it grabs all photos and videos at full resolution. For a standalone camera, I can manually grab the images from its memory card. (Or, if I get a new one, hook it up to wifi.)
Consolidate means taking the images from where the ingestion step put them, putting them into my central storage area, and organizing them into my preferred folder structure. The folder structure looks like YYYY/YYYYMMDD XXXXX/photo.jpg, where XXXXX is a short text summary of the event in that folder. This is a “date + event” model:
- If an event covers more than one date, use multiple folders, e.g.
20160719 Edinburgh trip20160720 Edinburgh trip
- If a date covers more than one event, use multiple folders, e.g.
20161019 Twiske molen damage20161019 Evening
- In case of no obvious event description, use the naked date, e.g.
20150406
The central storage area is an external hard drive that I mirror to a second drive nightly using SuperDuper. It also gets backed up to an external location as part of my Crashplan subscription.
The third stage is to tag the photos that have been organized. Photos coming off of modern smartphone already contain Exif information showing date and time, camera orientation, and GPS coordinates. These are main ones I care about. Sometimes the phone gets it wrong, though, for example if location services were off, or failed to capture my position correctly; or if I forgot to change the time zone after a flight. Photos from the A200 only have date and time information, no orientation or location data. In any case, it pays to do a pass over the photos to check and fix missing or inaccurate Exif data. (I can see myself writing a few scripts to help out with this.)
The final step is to share the photos: with friends and family, and also with my future self. I think I’ll use Google Photos for this, because it makes sharing with others easiest. Apple Photos has a nicer and more responsive interface for viewing photos locally (sharing with my future self), but if I want to share the whole library with Abi, and allow her to make new albums with its photos, I’d have to figure out Apple’s home sharing options and shared photo streams, and I just don’t trust Apple to have my very particular use case in mind. With Google Photos I can just set up a new Google account that both Abi and I have the password to. Google makes it easy to switch between multiple accounts these days.
It’s important that the tag and share steps are separate. I want as much metadata as possible to reside in the source image, not in the copy that the sharing service has. That makes it much easier to switch services in the future. I may trust Google more now than I did in the past (the Lindy effect comes into play here), but doing things like editing GPS coordinates only on the copy seems like a bad idea no matter what company runs the service.
(It looks like neither Google Photos nor Apple Photos use the “Image Description” Exif field for display purposes, which is a pity. Seeing as I have event description in the folder name anyway, I could update the photos with that text as well, and make the photos even more self-describing.)
Separating all of these steps might seem like a huge amount of bother. Google Photos and Apple Photos exist precisely to combine all of these steps, to make it easier and faster to get from taking the photo to sharing it. And that’s great, up to a point. But with 50,000 images, many of which are immeasurably precious to me, and a healthy mistrust of both hard disks and cloud services, I’m well beyond that point. I need more control.

With this new process, I have only got as far as the consolidation step. I still need to go through the consolidated images and fix the tags. But I can do that slowly, over time, and add them to the sharing service whenever I’m done with a folder. I felt that the consolidation step needed much more concentrated effort to get me over the initial hump, though. Tagging and sharing photos feels like fun, something I can do for an hour in an evening; comparing folders to find the missing images is work that I wanted to get done in as short a time as possible. Having a few days off was useful for just blasting through it.
Finally: watching myself gain weight in fast-forward over the last three years was not fun. Maybe this will be the spur I need to get back on the Flickr Diet.


 This presentation set the scene for the rest of the conference, briefly covering subjects like JavaScript 2 and the heated politics surrounding it, the emergence of offline support for web apps (Google Gears) and runtimes with desktop integration for web apps (AIR, Silverlight), and the evolution and convergence of JavaScript frameworks. Their demonstration of Google Gears’
This presentation set the scene for the rest of the conference, briefly covering subjects like JavaScript 2 and the heated politics surrounding it, the emergence of offline support for web apps (Google Gears) and runtimes with desktop integration for web apps (AIR, Silverlight), and the evolution and convergence of JavaScript frameworks. Their demonstration of Google Gears’  Mike talked about how in modern web development, the traditional barriers between designers and developers are breaking down. Designers need to be aware of the consequences of their choices, and how things like latency and concurrency will influence a feature. Developers need to increase their awareness of interaction design. This led to a discussion of how he feels that
Mike talked about how in modern web development, the traditional barriers between designers and developers are breaking down. Designers need to be aware of the consequences of their choices, and how things like latency and concurrency will influence a feature. Developers need to increase their awareness of interaction design. This led to a discussion of how he feels that Providing good accessibility for web content is hard enough; once you start building dynamic web apps, you’re practically off the map. Derek took the zoom/move control in Google Maps as an example of bad practice, showing how difficult it is for someone with only a voice interface to use. He walked through some more examples, with useful advice on how to make improvements in each case.
Providing good accessibility for web content is hard enough; once you start building dynamic web apps, you’re practically off the map. Derek took the zoom/move control in Google Maps as an example of bad practice, showing how difficult it is for someone with only a voice interface to use. He walked through some more examples, with useful advice on how to make improvements in each case. After lunch, Stuart Langridge put on his Master of EVIL hat, and tried to coax us to join him on the Dark Side by teaching us about all the things we can do to make a user’s experience on this hyperweb thingy as shitty and 1998-like as possible. Remember: if your app doesn’t use up all of a user’s bandwidth, they’ll only use it for downloading…well, something else. (“Horse porn” sounds so prejudicial.)
After lunch, Stuart Langridge put on his Master of EVIL hat, and tried to coax us to join him on the Dark Side by teaching us about all the things we can do to make a user’s experience on this hyperweb thingy as shitty and 1998-like as possible. Remember: if your app doesn’t use up all of a user’s bandwidth, they’ll only use it for downloading…well, something else. (“Horse porn” sounds so prejudicial.) Christian works for Yahoo!, and has for a long time been a great evangelist of
Christian works for Yahoo!, and has for a long time been a great evangelist of  PPK wrapped up the day with a case study of a genealogy/family tree application he is building. He walked through the decision processes behind:
PPK wrapped up the day with a case study of a genealogy/family tree application he is building. He walked through the decision processes behind: Brendan Eich is the man who invented JavaScript. There are few mainstream languages that have both been adopted so widely, and dismissed out of hand by so many. In the keynote presentation, Dion and Ben characterised Brendan Eich as wanting to use the JavaScript 2 (ECMAScript 4) spec to “just let him fix his baby”. That’s a pretty crude caricature of Brendan’s position, though. He is very keenly aware of all the problems in JavaScript as it stands right now. (And there are some really big problems.) With JS2 he is trying to take the best bits of JS1, and build a language for the next 5-10 years (or more) of the web.
Brendan Eich is the man who invented JavaScript. There are few mainstream languages that have both been adopted so widely, and dismissed out of hand by so many. In the keynote presentation, Dion and Ben characterised Brendan Eich as wanting to use the JavaScript 2 (ECMAScript 4) spec to “just let him fix his baby”. That’s a pretty crude caricature of Brendan’s position, though. He is very keenly aware of all the problems in JavaScript as it stands right now. (And there are some really big problems.) With JS2 he is trying to take the best bits of JS1, and build a language for the next 5-10 years (or more) of the web. This presentation did exactly what it said on the tin: an introduction to coding with
This presentation did exactly what it said on the tin: an introduction to coding with  Dan showed how to use some of JavaScript’s best features (prototypal inheritance, expando properties, using Functions as Objects, etc.) to produce some surprising results. Because of these techniques, JavaScript really is a language that can bootstrap itself into a better language. Very slick.
Dan showed how to use some of JavaScript’s best features (prototypal inheritance, expando properties, using Functions as Objects, etc.) to produce some surprising results. Because of these techniques, JavaScript really is a language that can bootstrap itself into a better language. Very slick.

 Douglas Crockford is one of the people most responsible for bringing JavaScript to its current level of maturity. He invented JSON, and wrote the
Douglas Crockford is one of the people most responsible for bringing JavaScript to its current level of maturity. He invented JSON, and wrote the 
 Jeremy tried to keep this light-hearted, but there was clearly some tension between the panellists. I was pretty tired by this point, though, and the thing I remember most is Alex berating Yahoo! (Douglas) for not open-sourcing the YUI framework and coming together with other toolkit developers to present a unified front to browser vendors. Other subjects that came up included Google Gears (again), how badly CSS sucks (I see their point, but I still like it anyway), and
Jeremy tried to keep this light-hearted, but there was clearly some tension between the panellists. I was pretty tired by this point, though, and the thing I remember most is Alex berating Yahoo! (Douglas) for not open-sourcing the YUI framework and coming together with other toolkit developers to present a unified front to browser vendors. Other subjects that came up included Google Gears (again), how badly CSS sucks (I see their point, but I still like it anyway), and 
