Of all the things I’ve learned this year, the most important is this: in a corporate/enterprise environment, you need to have a damn good reason for building a client-side forms application instead of a web app.
I reached this conclusion after building an in-house stock control system as a Windows forms app. Here’s how the architecture ended up:
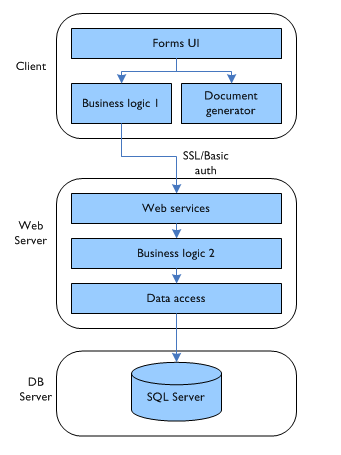
There’s nothing too controversial here, I’m sure you’ll agree. The most unusual thing is perhaps placing the burden of document generation (stock spreadsheets, production orders, invoices, etc.) on the client. The reason for this was cost and (supposed) simplicity: all the client machines using the application are equipped with MS Office, and so I could use Office automation to interact with a set of existing document templates. Buying a server-side component to generate Office documents (such as SoftArtisans OfficeWriter) seemed too expensive given the small size of the app, and creating a new set of templates in order to use a less expensive (or open source) PDF creator seemed too elaborate. (Don’t even get me started on working with WordML.)
In fact, document generation was the deciding factor in building a client-side app. In retrospect, this is probably the worst decision I made in 2005. The downsides were numerous:
Deployments
The obvious one has probably been the least painful. My experiences with .NET zero-touch deployments have been mixed at best. I’ve seen it working, and I’ve had it working myself, but the experience was awkward. Same with application updaters. Distributing a .msi setup package is simple and mostly foolproof, though. Nevertheless, it means the clients have to reinstall whenever a new version is available. If I had to do this again, I would choose one of the hands-off approaches, and work through the pain to get it up and running. Still if this were a web app, I wouldn’t have to deal with any of this.
Asynchronous communication
Easy enough in theory, but a bugger to get right in practice. The main idea is to keep the UI responsive while it is talking to the server by doing all the web service calls on a secondary thread. It was a lot of effort just to get progress bars working properly, and in the end I’m not entirely convinced it was worth it. As a UI specialist I am fully aware of the need for continuous feedback and a snappy feel, but for a small project like this I think it was overkill.
The .NET Datagrid component
Bane. Of. My. Life. Looks fine on paper, or in a demo, but COMPLETELY USELESS in any kind of real-world scenario. The amount of code you have to produce (either by writing it yourself, or by copying it from those who have suffered before you) to get even simple functionality working, like setting row heights, colouring the grid, or adding a drop-down list to a cell is staggering. If you want to do any serious client-side development with grids, you really must buy a third-party component.
In fact, the whole “rich user interface” benefit that has traditionally been the advantage of forms applications needs to be completely re-examined in the light of modern web apps, which draw upon javascript for better and more responsive interaction (Prototype, Script.aculo.us, Rico et al.), and CSS for visual flair. I can see a trend these days (in corporate environments) towards making client-side forms applications look and feel more like web pages, whereas just a few years ago it was the other way round.
Office automation with .NET
Not nearly as good as it should have been. Sure, I was able to re-use the existing templates to produce niceply formatted documents, but the Office API hasn’t improved significantly since 2000. Add to that the painful burning sensation of accessing it through COM Interop, and you get a whole heap of…yuckiness.
So with the benefit of hindsight, what should I have done instead? I’m glad you asked. Here’s the architecture for version 2:
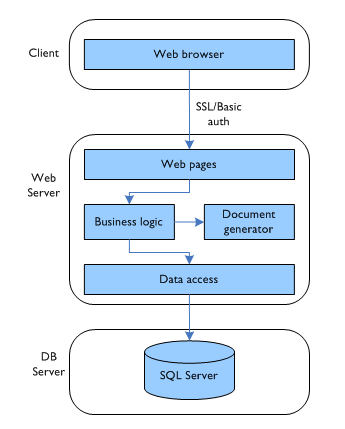
The Forms UI is going away, and will be replaced by a clean HTML/CSS/JS front-end. The business logic, which was distributed between the client and the server will now be purely server-based. (There will still be a certain amount of client-side validation via the ASP.NET validator controls, but that will be controlled from server-side code.) It might include some Ajax further down the line, but the initial development will be a simple, traditional page-based web app.
And document generation? Version 2 will be using the OpenDocument (OpenOffice.org) format. This is an XML format that is an awful lot easier to get right than WordML, meaning that I can use simple XmlDocument-based code on the server to create documents. The client machines will get OpenOffice 2.0 installed, and upon clicking a “Print” button will receive a response with a Mime type of application/vnd.oasis.opendocument.text. The web browser can then pass it straight to OpenOffice for viewing and printing. OpenOffice has come a long way in the last few years, and version 2.0 is excellent. It happily converts Word templates to its own format, so I don’t even have to do much work in converting all the existing assets.
There is definitely still a need for client-side forms applications. If you want to make use of local hardware features, such as sound (e.g. audio recording), graphics (dynamic graphing and charting), and peripheral devices (barcode scanners), or if you want to have some kind of off-line functionality, you’re going to have to stick closely to the client. But for typical corporate/enterprise applications–staff directory, timesheets, CRM, and every bespoke data-entry package under the sun–I can see no compelling reason to consider a forms application as the default architecture.